Home » File Systems (Page 4)
Category Archives: File Systems
MICA: A Holistic Approach to Fast In-Memory Key-Value Storage
Hyeontaek Lim, Dongsu Han, David G. Andersen, and Michael Kaminsky in Proceedings of the 11th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’14). April 2-4, 2014, Seattle, WA.
It’s time to turn attention to key value stores. There are quite a few papers on this subject. Seemingly simple, they turn out to be an important storage mechanism. I had a delightful discussion about them over the weekend with Keith Bostic, who knows a fair bit about key-value stores (being the author of one of the most widely used KV stores.) Of course, I have discussed some KVS already: MassTree, NVMCached, and SILT.
I’m going to continue looking at key-value stores (KVS) by starting with MICA. It is neither the first, nor the latest, work in this area, but it seems like a good place to start really describing key value stores in this space. I have quite a few to cover so let’s get started.
MICA is a scalable in-memory key-value store that handles 65.6 to 76.9 million key-value operations per second using a single general-purpose multi-core system. MICA is over 4–13.5x faster than current state-of-the-art systems, while providing consistently high throughput over a variety of mixed read and write workloads.
It is an interesting system in that the authors decided to look at making their KVS tunable – it can serve as a cache (which means items can be thrown out by the KVS as space becomes scarce) or it can serve as storage (which means items cannot be removed from the KVS by the system itself, though it permits the applications using it to do so.)
To achieve this, they propose a series of data structures tuned to the task: circular logs, lossy concurrent hash indexes, and bulk chaining. Their goal is to provide high performance through low contention. They utilize dpdk for fast network processing. They split their data structures so they independently handle caching and storage separately. I might argue that this makes it two systems fused together, but let’s give them the benefit of the doubt at this point by calling it “generality”.
One of the concerns they try to address is the hot key issue. In many KVS systems they get terrific performance on synthetic workloads because they use a uniform distribution. In the real world, particularly for web objects, the workloads tend to be mostly cold with a small subset of the keys that are hot. Further, these keys change over time.
They do restrict their domain somewhat to make the problem more tractable. For example, they do not handle large items – everything must fit within a single network packet. For systems that require larger items, they suggest using a separate memory allocator. Their argument is that the extra indirection cost is a marginal increase in total latency. They are optimizing for the common case. Another aspect they exclude is durability. That makes sense – they are only implementing an in-memory KVS, so durability is not a logical part of their work. This also plays well in terms of performance, since persistence makes things much more complicated.
So what do they want to achieve with MICA?
- High single-node throughput
- Low end-to-end latecy
- Consistent performance across workloads
- Support small (but variable length) key-value objects
- Support basic KVS operations: get, put, delete
- Work efficiently on commodity hardware
They propose achieving this using a combination of design choices:
- Parallel data access – in fact, they mean read access, as they do not parallelize these, as the cost is too high.
- Optimized network overhead – as noted previously, they use dpdk to achieve this
- Efficient KV structures – this includes dual memory allocators (one optimized for caching the other for store) and efficient index implementations.

There are some interesting characteristics to this system, including the fact that it employs dangling pointer handling. Rather than remove pointers from the index, they allow the pointers to become invalid and instead trap that condition. The paper describes how they do that in more detail.
They also use an interesting “prefetcher” to encourage efficient memory loading. This is done by receiving requests in bursts and scheduling those requests to be processed “soon” to this prefetch step.
 Their evaluation of the system tries to focus on a range of workloads, varying key and value size as well as the range of operations being performed, with a read intensive workload being 95% reads and 5% writes. A write intensive workload is split evenly.
Their evaluation of the system tries to focus on a range of workloads, varying key and value size as well as the range of operations being performed, with a read intensive workload being 95% reads and 5% writes. A write intensive workload is split evenly.
They also look at how the key space is handled. In the “Exclusive Read, Exclusive Write” paradigm (EREW) each core of the system is responsible for handling both reads and write for a given key (or range of keys more likely). In the “Concurrent Read, Exclusive Write” paradigm (CREW), any core may satisfy a read for the key, but only one core may satisfy a write operation for the core. This is a hat tip towards the cost of “bouncing” control of the cache lines between cores and we will see this approach used by other systems as well. One interesting question that this reminds me of each time I read about this model is what impact, if any, the Level 3 cache might have on this. Level 1 and 2 caches are traditionally per core but Level 3 is typically per socket. Thus, things stored in L3 cache are substantially faster to access than RAM. Something to consider, perhaps.
The paper has an extensive evaluation section and, of course, they demonstrate how their solution is substantially faster. One interesting aspect to their evaluation is that they claim that each component of their design decision is important in enabling them to achieve their target performance. To do this, they evaluate each individual aspect of their design decision. For example for their parallel data model, they evaluate the variations on their choice and demonstrate that CREW is only faster with read skewed workloads. They even go so far as to model Concurrent Read Concurrent Write (CRCW) workloads and point out that the cache overhead blunts the benefits of the concurrency.
To make this point on their choice of network implementations, they take MassTree and convert it to use dpdk, which yields a substantial performance improvement. While they argue that their key indexes also contribute, they do not have a distinct break-out of that implementation and fall back to pointing out how they work better, even in CREW than MassTree.
There are certainly grounds to criticize MICA. For example, they do choose workloads that fit well with their available resources. I suspect that once they become resource constrained (e.g., cache) that the performance will drop substantially. However, it provides an interesting contribution in the space and does point out how picking your data structures carefully can make a tremendous difference in the overall performance of the system.
NVMCached: An NVM-based Key-Value Cache
NVMCached: An NVM-based Key-Value Cache
Xingbo Wu, Fan Ni, Li Zhang, Yandong Wang, Yufei Ren, Michel Hack, Zili Shao, and Song Jiang, in Proceedings of the 7th ACM SIGOPS Asia-Pacific Workshop on Systems, 2016.
This is a short (6 page) paper that discusses the challenges of taking a memory based key-value cache (e.g., memcached) and converting it to use a non-volatile memory. Because the authors do not have NVM available, they focus on simulating it using DRAM. They simulate behaviors by using appropriate cache flushes and fence. In fact, they use CLFLUSH and MFENCE, which may be a bit more than is required.
Here is an interesting thing for people familiar with Intel processor architecture for more than about the past 15 years: the CPUs no longer provide strong ordering guarantees. If you’ve learned or refreshed your knowledge about the memory consistency models more recently, then you are likely already familiar with this. One of the interesting issues with NVM is that we need to think about memory consistency in a way that’s never been required previously. The authors of this paper do this.
They note that flushes are expensive; they argue for using “consistency-friendly data structures” for minimizing the number of flushes required, which certainly makes sense, particularly given that they are expensive. Some operations (like anything with the LOCK prefix) are performed atomically as well and are conceptually similar; both tie into the processor’s cache architecture (for those that have been around a while, the cache line semantics for LOCK were introduced around 1995.)
One of the important observations in this paper is that the reason to use NVM is that it allows fast restart after a system failure, such as a crash or power event. For memcached, there are users that are asking for persistence. Even if the service is only a cache, it turns out that offloading to the cache can be a powerful mechanism for improving overall throughput, but the larger the cache becomes, the higher the cost when the cache gets tossed after a system crash.
However, this also simplifies the problem at hand: discarding data in this type of system is of minimal concern. They utilize checksums to detect damaged data structures, which alleviates their need to perform ordered write operations; they reorganize their data structures to permit changes with only infrequent fencing. They point out the problem of zombie data (data that is deleted, then the system crashes, so the data returns after the system reboots). To prevent this situation they choose to split their data structures.
The checksums prove to be much less expensive than flush; the authors claim up to 20x faster (my own reading indicates that using the optimized CRC32 built into modern Intel CPUs the cost is just over 1 clock cycle per byte checksummed, so a 64 byte cache line would have a cost of approximately 70 clock cycles; on a 2.0GHz processor, that would be roughly 17.5 nanoseconds, which certainly is somewhere between 5 and 20 times faster than writing back a cache line.
The authors also touch on the challenges of memory allocation. Memory fragmentation is something we often fix in dynamic memory by rebooting the machine. However, now we have the storage level problem with fragmentation; fixing this involves write amplification. They organize their allocation strategy by observing there is considerable locality across the KV store. They combine a log structured allocation scheme with a “zone based” allocation model and attempt to combine cleaning, eviction, and updates to minimize the impact on performance. They also use DRAM to track access information as part of their LRU implementation. This creates a burden on crash recovery, but benefits from significant improved runtime performance.
They also implement a DRAM write combining cache; the idea is that when an item is detected to be “hot” the item is cached in DRAM. Those hot items will thus be discarded if the system crashes.
Their evaluation is against a modified version of memcached. They utilize four Facebook traces; interestingly they do not use one (VAR) because “it is write-dominant with only a few distinct keys touched.” I am not certain that I see why this makes it unsuitable for use, though I suspect they do not obtain favorable behavior in the face of it.
They evaluate the performance of native memcached versus their NVM-enhanced version with a series of micro-benchmarks after a restart event. They show that in several cases it takes more than 1 billion requests before the performance of the DRAM memcached to converge with the NVM enhanced version. When they use the “real world” Facebook memached traces, they observe that three of the benchmarks show comparable performance. Two of them, SYS and VAR, show substantially better performance. Both benchmarks are write intensive. I admit, this surprised me, since I am not certain why writing to (simulated) NVM should be substantially after than writing to DRAM.
Overall, it is interesting work and touches on important challenges for working with NVM as well as improving system performance.
SILT: A Memory-Efficient, High-Performance Key-Value Store
Hyeontaek Lim, Bin Fan, David G. Andersen, Michael Kaminsky, in Proceedings of the 23rd Symposium on Operating Systems Principles (SOSP ’11), October 23-26, 2011, Cascais, Portugal.
In this paper, we have an interesting hybrid key-value store; part of the store is in DRAM, while the rest of it is stored in flash storage. The authors have focused on optimizing the performance of the store across the specific media chosen, which leads to some interesting choices and observations.
SILT (Small Index Large Table) is a memory-efficient, highperformance
key-value store system based on flash storage that
scales to serve billions of key-value items on a single node. It requires
only 0.7 bytes of DRAM per entry and retrieves key/value
pairs using on average 1.01 flash reads each. SILT combines new
algorithmic and systems techniques to balance the use of memory,
storage, and computation. Our contributions include: (1) the design
of three basic key-value stores each with a different emphasis on
memory-efficiency and write-friendliness; (2) synthesis of the basic
key-value stores to build a SILT key-value store system; and (3) an
analytical model for tuning system parameters carefully to meet the
needs of different workloads. SILT requires one to two orders of
magnitude less memory to provide comparable throughput to current
high-performance key-value systems on a commodity desktop
system with flash storage.
Thus, to achieve optimal performance they construct a hybrid ensemble of key-value stores that are optimized to particular underlying media.
They start early with their performance observations, and continue this pace throughout the paper. Thus, they point out that they have a small memory requirement (0.7 bytes per key value) and only a single read from flash required:
 This fits well with their observation that memory efficiency is critically important for scalable key-value stores. Their system saturated the capabilities of their hardware with 46,000 lookups per second, though this doesn’t guarantee that it will do so on newer, faster hardware (and we will get to several current KV stores.
This fits well with their observation that memory efficiency is critically important for scalable key-value stores. Their system saturated the capabilities of their hardware with 46,000 lookups per second, though this doesn’t guarantee that it will do so on newer, faster hardware (and we will get to several current KV stores.
 Figure 2 (from the paper) provides a basic description of the SILT architecture. From this, we can see the three distinct types of stores that are used within their implementation:
Figure 2 (from the paper) provides a basic description of the SILT architecture. From this, we can see the three distinct types of stores that are used within their implementation:
- LogStore – uses a CPU-efficient cuckoo-hash based only upon a tag derived from the full key (20 bytes). The benefit of this approach is that it avoids accessing the flash memory if the key is not present. It is probabilistic, in that a key might not be present in Flash with some low probability.
- HashStore – uses a memory-efficient storage model for their cuckoo flash table. These stores are immutable and are stored in flash.
- SortedStore – They use an entropy-coded trie, which provides a very space efficient indexing mechanism: the average according to the authors is 0.4 bytes per key. Given that keys are 160 bits (20 bytes), which means the index is 64 bits (8 bytes). The authors provide us with an impressive list of specific optimizations they have applied to sorting data, packing indexes, intelligent (non-pointer) based addressing,
They also provide us with pretty figures to graphically lay out their data structures. First, Figure 3, which shows the in-memory cuckoo hash table:
 Note the fact the key-value insertions are logged to the flash storage.
Note the fact the key-value insertions are logged to the flash storage.
When we move onto HashStore, they show us how the structure of the data is moved from insertion order to hash sorted order as the data is moved from memory to flash.
 Recall that once written to Flash, the HashStore is immutable – so this order will remain fixed.
Recall that once written to Flash, the HashStore is immutable – so this order will remain fixed.
Of course, one of the important aspects of a key-value store is the ability to look up the data quickly. Thus, they also show us how they sort data using a prefix tree (Trie). This is a key aspect of their SortedStore:

The in-memory Trie, permits them to rapidly find the corresponding data in Flash. This is one of their key motivations for very efficient encoding of the Trie: it ensures they can store it in memory. Once they can no longer store the indices in memory the lookup system will become I/O bound (to the Flash, in this case).
Figure 6 then shows how they actually encode the length of the tree in each direction, and how it is entropy encoded: There is some serious thought that has gone into their layout. They do admit, however, that they are not providing crash tolerance: there will be data that was stored in DRAM that cannot be recovered after a crash. They do not discuss the use of NVM for achieving this. Instead, they suggest a synchronous write mechanism in which the write blocks until the log data has been written to the flash-based log.
There is some serious thought that has gone into their layout. They do admit, however, that they are not providing crash tolerance: there will be data that was stored in DRAM that cannot be recovered after a crash. They do not discuss the use of NVM for achieving this. Instead, they suggest a synchronous write mechanism in which the write blocks until the log data has been written to the flash-based log.
One of the interesting aspects of their performance evaluation is the recognition that they have quite a few parameters that must be chosen. Thus, they spend more than a page of the paper just discussing the relative merits of the trade-offs involved in selecting various parameters. They consider write amplification (the need to write more than just the data being preserved), read amplification (performing reads only to discover the data that you seek is not present), memory overhead (how much DRAM is used), and update rate versus flash life time. This latter point is an interesting one to keep in mind when reading about non-volatile memory: it wears out. There is a certain amount of degradation that occurs in the underlying physical medium each time it is erased and re-used. The specific details are dependent upon the characteristics of the medium, but it is an issue to keep in mind.
The evaluation of SILT is certainly interesting. They choose not to compare to any other KV system and instead focus on the performance of their system using a variety of fairly standard loads (YCSB) as well as simple get/put key operations as micro-benchmarks. They end up claiming they they can lookup almost 45k keys per second in the slowest of their hybrid stores. When combined, they indicate they can achieve almost 58k get operations per second on a single core. As they move to multiple cores they see some further improvement (180k get operations per second for data that is already in memory).
SILT offers some interesting observations, particularly about highly efficient use of memory and novel indexing schemes.
Cache Craftiness for Fast Multicore Key-Value Storage
Yandong Mao, Eddie Kohler, Robert Morris, in Proceedings of the 7th ACM european conference on Computer Systems (Eurosys ’12), pp. 183-196, Bern, Switzerland, April 10 – 13, 2012.
In this work, the authors build a key-value system called MassTree. This is an in-memory Key-Value store (I will look at several of them, in fact). What is novel about this particular variant is the authors focus on providing a high-performance parallel access implementation and the mechanisms by which they achieve this.

MassTree support arbitrary-length keys; it assumes nothing about the keys (so they may be binary data). It uses B+-trees for storage organized into a Trie structure. The B+-tree stores a fixed slice of the key; the Trie connects the various slices together. This use is interesting, since most of the cases I’ve seen of Tries are for strings, as they do an excellent job of managing overlapping string data (prefix trees). The authors use this for binary keys. There is nothing inherently more difficult about binary versus string keys (since they are equivalent) but this choice makes the solution very flexible, as it is not particularly data dependent. This basic layout is shown in Figure 1 (from the paper).
One of the challenges with concurrent data structures is how to handle the common case – no collisions – with minimal performance overhead. The classic mutual exclusion model (or reader/writer locks) involves a certain amount of overhead, even for non-contended locks, because of the need to perform interlocked operations against shared (common) memory where the locks are maintained. The system implemented by the authors does not require any locking for readers (lookups). Updates are done with locks local to the CPU, which helps minimize the contention of typical locks.
One interesting observation is that their choice of this hybrid Trie/B+-tree structure was motivated by prior systems that struggled with performance in the presence of variable length keys. In MassTree, the rate limiting factor for queries is the cost of walking the tree. They minimize this by using “a wide fan-out tree to reduce tree-depth, prefetches nodes from DRAM to overlap fetch latencies, and carefully lays out data in cache lines to reduce the amount of data needed per node.”
Hence, my interest in this paper: these all seem to be important lessons for persistent memory as well, where the latencies are somewhat larger than for DRAM. Further, the authors are concerned about correctness. They have not looked at persistence (and recoverable consistency), so there is still further work for me to do should I investigate it further.
The authors conclude by claiming the following contributions:
First, an in-memory concurrent tree that supports keys with shared prefixes efficiently. Second, a set of techniques for laying out the data of each tree node, and accessing it, that reduces the time spent waiting for DRAM while descending the tree. Third, a demonstration that a single tree shared among multiple cores can provide higher performance than a partitioned design for some workloads. Fourth, a complete design that addresses all bottlenecks in the way of million-query-per-second performance.
Their emphasis on correctness and cache efficiency is certainly an attractive aspect of this work.
The driving considerations for their design were: efficient support of many different key distributions including binary and variable length keys, with common prefixes; fine grained concurrent access for high performance parallel access, and cache efficiency through optimal data placement and prefetching.
The authors establish the characteristics of their tree structure, including data placement. These make reasoning about their tree characteristics simpler. For example, they note that MassTree does not guarantee that it is a balanced structure. However, due to the way the tree itself is structured, they have the same algorithmic cost: O(l log n) comparisions, where l is the length of the key and n is the depth of the tree.
As a pragmatic check on their implementation, they also use a partial-key B-tree (pkB-Tree) for comparison. Despite the fact the pkB-Tree is balanced, the authors note that MassTree performs favorably well on several benchmarks. The authors go into detail about their implementation details, including the construction of border nodes and interior nodes, as well as how they lay out data (again, with an eye towards cache line efficiency).
 To achieve this efficiently, they use a versioning scheme. A node has a version number. To modify the node, a given processor must update the version to indicate that it is changing the node. A reader will snapshot the version at the start of the read, and compare it at the end of the read. If it changed, the reader knows the state may have changed and can retry the read operation (essentially a variant of software transactional memory). The detailed diagram of this is shown in Figure 3 (from the paper).
To achieve this efficiently, they use a versioning scheme. A node has a version number. To modify the node, a given processor must update the version to indicate that it is changing the node. A reader will snapshot the version at the start of the read, and compare it at the end of the read. If it changed, the reader knows the state may have changed and can retry the read operation (essentially a variant of software transactional memory). The detailed diagram of this is shown in Figure 3 (from the paper).
The paper describes the concurrency model in the face of conflicting writers as well. By keeping their lock in the same cache line as their data, they exploit the cache coherence protocol. The authors note that lock-free operations have comparable cache behavior (e.g., compare-and-swap or link-load-store-conditional).
 Indeed, much of the rest of the technical content of the paper is explaining why their approach is correct – an essential point for concurrent access systems. Without that, there really is not much point!
Indeed, much of the rest of the technical content of the paper is explaining why their approach is correct – an essential point for concurrent access systems. Without that, there really is not much point!
While brief, their discussion about value storage is interesting: their measurements are done assuming that values will be small. They state they have a scheme for managing large values as well, via a separate allocator. While they do not claim this, my observation is that a “real world” system would likely need to have some hybrid form of this.
MassTree is an in-memory key-value store. To provide persistence, they rely upon a write-behind log scheme. When used via the network interface, the writes are not guaranteed. To minimize the loss window, they choose a 200 ms timer. Thus, the log is written to disk every 200 ms. They do not evaluate this persistence model, offering it to us as an explanation that persistence is not incompatible with performance.
This last point is an interesting one, especially when considered in the context of NVM: what are the trade-offs. The authors hint at this, but do not explore this space.
For those interested, a version of the source code can be found here: https://github.com/kohler/masstree-beta
MRAMFS: A compressing file system for non-volatile RAM
Nathan K. Edel, Deepa Tuteja, Ethan L. Miller, and Scott A. Brandt in Proceedings of the 12th IEEE/ACM International Symposium on Modeling, Analysis, and Simulation of Computer and Telecommunication Systems (MASCOTS 2004), Volendam, Netherlands, October 2004.
This paper allows me to provide both a file systems paper and look at an interesting approach to byte-addressable non-volatile memory (NVM).
We have developed a prototype in-memory file system which utilizes data compression on inodes, and which has preliminary support for compression of file blocks. Our file system, mramfs, is also based on data structures tuned for storage efficiency in non-volatile memory.
One of the interesting aspects of NVM is that it has characteristics of storage (persistence) and memory (byte-addressability). Storage people are used to having vast amounts of time to do things: it is quite difficult, though not impossible, to do anything computationally with data that will be an important factor when it is combined with the overhead of I/O latency to disk drives. In-memory algorithms worry about optimal cache line usage and efficient usage of the processor, but they don’t need to worry about what happens when the power goes off.
Bringing these two things together requires re-thinking things. NVM isn’t as fast as DRAM. Storage people aren’t used to worrying about CPU cache effects on data resilience.
So mramfs looks at this from a very file systems centric perspective: how do we exploit this nifty new memory to build a new kind of RAM disk: it’s still RAM but now it’s persistent. NVRAM is slower than DIMM and hence it makes sense to compress it to increase the effective data transfer rate (though it is not clear if that really will be the case.)
I didn’t find a strong motivation for compression, though I can see the viability of it now, in a world in which we want to pack as much as we can into a 64 byte cache line. The authors point out that one of the previous systems (Conquest) settled on a 53 byte inode size. The authors studied existing systems and found they could actually compress down to 20 bytes (or less) for a single inode. They achieved this using a combination of gamma compression and compressing common file patterns (mode, uid, and gid). Another reason for this approach is they did not wish to burden their file system with a computationally expensive compression scheme.
 In Figure 1 (from the paper) the authors provide a graphic description of their data structures. This depicts a fairly traditional UNIX style file system, with an inode table, name space (directories), references from directory entries to the inodes. Inodes then point to control structures that eventually map to the actual data blocks.
In Figure 1 (from the paper) the authors provide a graphic description of their data structures. This depicts a fairly traditional UNIX style file system, with an inode table, name space (directories), references from directory entries to the inodes. Inodes then point to control structures that eventually map to the actual data blocks.
The actual memory is managed by the file system from a single chunk of non-volatile memory; the memory is virtually addressed and the paper points out that they don’t actually care how that mapping is achieved.
Multiple inodes are allocated together in inode blocks with each block consisting of 16 (variable length) inodes. The minimum size of a block is 256 bytes. inodes are rewritten in place whenever possible, which can lead to slack space. If an inode doesn’t fit within its existing space, the entire block is reconstructed and then written to a new block. Aftewards, the block pointer is changed to point to the new block. Then the old block is freed.
One thing that is missing from this is much reasoning about crash consistency, which surprised me.
The authors have an extensive evaluation section, comparing to ext2fs, ramfs, and jffs2 (all over RAM disk). Their test was a create/unlink micro-benchmark, thus optimizing the meta-data insertion/deletion case. They then questioned their entire testing mechanism by pointing out that the time was also comparable to what they achieved using tmpfs building the openssl package from source. Their final evaluation was done without the compression code enabled (“[U]nfortuantely, the data compression code is not yet reliable enough to complete significant runs of Postmark or of large builds…”). They said they were getting about 20-25% of the speed without compression.
Despite this finding, their conclusion was “We have shown that both metadata and file data blocks are highly compressisble with little increase in code complexity. By using tuned compression techniques, we can save more than 60% of the inode space required by previous NVRAM file systems, and with little impact on performance.”
My take-away? This was an early implementation of a file system on NVM. It demonstrates one of the risks of thinking too much in file systems terms. We’ll definitely have to do better.
The Log-Structured Merge Tree (LSM-Tree)
Patrick O’Neil, Edward Cheng, Dieter Gawlick, Elizabeth O’Neil in Acta Informatica, , Volume 33, Issue 4, pp 351–385.
This paper does not relate to non-volatile memory, but we will see Log-Structured Merge Trees (LSMTs) used in quite a few projects. From the abstract:
The log-structured mergetree (LSM-tree) is a disk-based data structure designed to provide low-cost indexing for a file experiencing a high rate of record inserts (and deletes) over an extended period. The LSM-tree uses an algorithm that defers and batches index changes, cascading the changes from a memory-based component through one or more disk components in an efficient manner reminiscent of merge sort. During this process all index values are continuously accessible to retrievals (aside from very short locking periods), either through the memory component or one of the disk components.
So LSMTs originate from concerns about the latency issues around disk drives.
In a nutshell, the challenge with disk drives are they have mechanical parts that must be moved in order to read the data. Data is written in concentric bands around the center. The angular velocity of the disk platter is the same, but of course the surface velocity is lowest towards the center and fastest towards the outer edge. The disk drive “head” is moved in and out to read from each of those concentric circles. Since it can only read what is beneath the head, it also must wait for the desired data to rotate under the head. This is one reason why faster disk drives (usually measured by the rotations-per-minute number) provide faster response times. On the other hand, faster disk drives generate more heat and are more expensive to build.
Thus, an important consideration for file systems working on rotating media is the latency to perform random access. Tape drives have the highest latency, since we have to reposition the tape to get to another location and read its data (there are other complexities as well, such as the fact that tape benefits most from streaming write). Hard disk drives (HDDs) are not so bad as tape drives in general (though SMR drives act much like tape drives, which is one reason I mention that here.) Solid State Disks are even better than disk drives, though even for an SSD random access is slower than sequential access – but both are much faster than HDDs.

Some of those papers that I have yet to cover describe the concept of a log-structured file system. One of the things that I learned when working on the Episode File System was that converting random I/O to sequential I/O was definitely a win (so was asynchronous logging). It is this observation: converting random I/O to synchronous I/O that provides the benefit of using journaling techniques (the “log”).

So LSMTs capitalize upon this advantage. Note that an LSMT is not a single data structure; rather it is a general technique for working with systems where insert and delete are the common operations, such as meta-data within a file system, or (key,value) tuples in a key-value store. It also points out that reading large sequential block is generally more efficient; they cite IBM when noting that a single page read from the DB2 Database takes approximately 10 milliseconds. A read of 64 continuous pages costs about 2 milliseconds per page (125ms total). So batching I/O operations is also an important mechanism for improving performance.
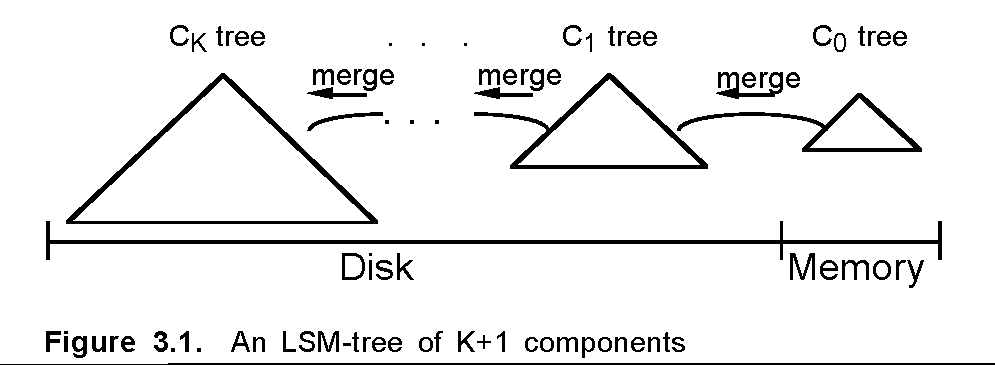
So what is an LSMT? “An LSM-tree is composed of two or more tree-like component data structures.” From there the authors describe their initial case: where one tree is memory resident and the other is disk resident. Note, however, this is the smallest set for a valid LSMT. Systems with more than two have been built – and one way to use non-volatile memory (NVM) is to add it as another layer to an LSMT.

Figure 2.1 (from the paper) shows the high level structure of the LSMT – a tree-like structure at each level of the storage hierarchy; these levels can have different characteristics, such as being ephemeral (in memory) or persistent (on disk, tape, SSD, etc.) Figure 2.2 provides greater detail, showing how data is merged from one level to the next (“rolling merge”). Figure 3.1 shows a generalization of the LSMT, in which data is migrated from one level of the storage hierarchy to the next.
Figure 6.1 then helps motivate this work: data that is seldom accessed (which is most of the data) is “cold” and can be stored in lower cost storage. Data that is frequently accessed (which is a small amount of the data) is “hot” and benefits from being stored in faster but more expensive storage. Indeed, there is a substantial body of work at this point that demonstrates how data tends to cycle from being hot to being cold. Thus, there is a period of migration for “warm” data. This also helps explain why having a multi-stage model makes sense. This behavior is quite general, in fact. Disk drives are constructed with caches on them. The cache is for the hot data, the disk storage for the cold data. SSDs are often structured with multiple classes of NVM; a small amount of expensive but fast NVM and then a larger amount of less expensive (often block oriented) NVM. Even CPUs work this way (as I will be discussing ad nauseum), where there are multiple levels of caching: L1 cache is small but very fast, L2 cache is larger and slower (and cheaper), L3 cache is again larger and slower. Then we get to memory (DRAM) which is even slower. That’s all before we get to storage!
This is quite a long paper: they describe how data is merged from one level to the next as well as do an in-depth analysis of cost versus performance. But I will leave ferreting out those details to the interested reader. I got what I came for: a basic description of the tiered nature of LSMTs and how we can use them to make storage more efficient without driving up costs.
The Cambridge File Server
The Cambridge File Server
Jeremy Dixon, in ACM SIGOPS Operating Systems Review, Volume 14, Number 4, pp 26-35, 1980, ACM.
Cambridge was certainly a hotbed of systems work in the 1970s (not to say that it still is not). They were looking at very different architectures and approaches to problems than we saw from the various Multics influenced systems.
The introduction to this paper is a testament to the vibrant research work being done here. They author points to the Cambridge ring, which was their mechanism for implementing a shared computer network and a precursor to the Token Ring networks that followed. The CAP computer was part of this network, and the network included a separate computer that had a vast amount of storage for the time – 150MB. That common storage was used for both “filing systems” as well as “virtual memory”. This computer ran the Cambridge File Server and implemented the functionality that was explored in the WFS paper.
They identify key characteristics of their file server:
- Substantial crash resistance.
- Capabilities used to control access.
- Atomic file updates.
- Automatic “garbage collection” of storage space
- Fast transfer to random accessed, word-addressable files.
The authors make a point of noting there are only two classes of objects in their system: files and indices. I found this interesting because it echos the hierarchical file systems models that encouraged me to start this journey in the first place.
They define a file: “… a random access sequence of 16-bit words whose contents can be read or written by client machines using the following operations”. The operations that follow are read and write. They go on to define an index: “… a list of unique identifiers, and is analogous to a C-list in capability machines”. The three operations here are: preserve, retrieve, and delete. This permits entries to be added, found, and removed.
The storage controlled by the file server thus appears to its clients as a directed graph whose nodes are files and indices. Each file or index operation is authorised by quoting the object’s unique identifier to the file server, and UIDs are 64 bits long with 32 random bits. Each client, therefore, can access only some of the nodes in the graph at any time, namely those whose UIDs he knows, an dthose whose UIDs can be retrieved from accessible indices.
Thus, they actually have a graph file system that may in fact consist of nodes that are not connected – essentially a pool of disconnected trees that can be traversed if you know how to find the tree, but is effectively hidden otherwise. They do point out that the sparse space may not be sufficient protection (though I suspect a small finite delay on an invalid lookup with discourage brute force browsing).
Objects are deleted when they cannot be found from some distinguished root index; the paper describes that each client is given its own entry in the root index, pointing to the client specific index. There is the implication that they will scan the storage looking for such unreferenced objects that can be cleaned up and indeed they refer to a companion paper for a detailed description of this garbage collector.
Their argument for this omission is that it relieves the client of the burden of managing object lifetimes (“… removes from the clients the burden of deciding when to delete an object…”)
Storage space is segregated into “data” and “map” blocks. The data blocks contain object contents. The map blocks contain meta-data. New files are stored as a single data block. As the file grows in size, map blocks are inserted to create a tree of up to three levels deep.
The paper then turns its attention to the atomic nature of the updates to the file server. The author points out that moving from consistent state to consistent state may require multiple distinct changes. Since failures can interrupt you between any two operations, the discussion revolves around ways in which this can be robustly implemented in atomic and recoverable fashion. The author points out that the overhead in protecting against this class of failures has substantial overhead. Given that not all files require this level of robustness, he proposes that the file server provide two separate classes of service for data files. Map blocks are maintained in consistent fashion because they have the file server’s meta-data within them and the consistency of the file server’s control information needs to be preserved.
Much of the detail in the paper at that point involves describing the structure of the meta data and how it is used to implement atomic operations on the file server. The paper provides a detailed description of how transactions are implemented within this system. The fact they describe implementing a complete transactional file system, discuss the ramifications of providing user level transactional data storage, and come up with a hybrid model does make this an impressive piece of early work. We will see journaling file systems more than once as we move forward.
The balance of the paper discusses how this has worked within their systems at Cambridge. It is interesting and they tie some of the implementation efficiency to the environment of the Cambridge Ring itself. This is a production file server and the author notes that it is used by a variety of computers (including different operating systems) within their environment successfully.
Its relatively quick response has allowed it to be used to record and play back digitised speech in real time. The interface provided seems both simple and suitable for a variety of purposes.
Impressive indeed.
WFS: A Simple Shared File System for a Distributed Environment
Daniel Swinehart, Gene McDaniel, and David Boggs, in Proceedings of the Seventh ACM Symposium on Operating Systems Principles, pp. 9-17, 1979, ACM.
This file system was developed at Xerox’s Palo Alto Research Center (PARC), which produced a string of amazing advances in the nascent computer technology area in the 1970s.
Woodstock was “an early office system prototype”. The authors’ description of Woodstock sound much like early word processing systems, such as those pioneered by Wang Laboratories in the same time frame. The ability to share data between these systems turns out to be surprisingly important. Local storage space was used to track the current work, but then centralized storage provides an efficient way to store them and make the work available to others.

This is the environment that gave rise to WFS. Because Woostock already existed and provided its own hierarchical document directory structure, WFS did not need to provide such a mechanism. In fact, WFS only provided four classes of operations:
- I/O operations to read and write blocks of data within files
- Creating/Destroying resources: file identifiers (FIDs) and storage blocks (pages)
- Managing file properties, including page allocation data
- Providing maintenance functions
The actual implementation is surprisingly simple. Indeed the authors’ state that it took two months to build it.
Figure 1 (from the original paper) describes the format of a request/response packet, showing the basic information exchange model. It is interesting to note that the entire message fits within a small amount of memory and includes an end-to-end checksum.
There are a number of simplifying options with WFS:
- The namespace for files is flat; there is no hierarchical structure.
- The file structure is simple (Figure 2).
- The protocol is stateless and each operation is idempotent. This simplifies error handling since a lost message can be re-transmitted safely, with no fear that repeating it will cause problems.
- Operations are client initiated. The server never initiates an operation.
- Clients have limited mutable state. The server does not permit changing its own state directly from the client.
This simiplicity does limit the generality of WFS, but it also demonstrates an important abstraction that we will see used (and re-used) in subsequent systems: a file can be treated as a block structured device (a “disk”) in an interesting and transparent fashion.

Figure 3 describes the layout of the (stateless) data exchange format used by WFS.
Figure 4 shows the layout of the file directory table which is a contiguous and fixed-size region on disk at a known disk location. This is a fairly common characteristic of on-disk file system formats, having a known location where meta-data is to be found.
Note that Figure 4 also shows how the file’s allocated storage is described via direct and indirect block references organized into a tree structure. Again, this will be a recurring model that occurs in file systems; it combines the flexibility of supporting efficient space utilization, ability to describe variable sized files, and efficient utilization of block-addressable storage.
This simple mechanism permits their clients to utilize a flexible storage mechanism without forcing the file server to support any of the mechanisms the client already provides, such as the hierarchical document name space, management of documents and their structure, etc. This separation of concerns yields an elegant and simple implementation model for their file server.

There are some interesting implementation details described in the paper:
- Write operations are validated by reading the data page. Thus, writes become compare and swap operations that prevents concurrent access from inadvertently overwriting changes made by another client. It would be rather inefficient to rely upon this mechanism, but it helps prevent out-of-order packet processing in an unreliable network. The downside to this is they must read the data before they can write it.
- They use a write-through cache. Thus, the cache is really for read efficiency, not write efficiency. This should help mitigate the write inefficiency.
- Most of their caching is done against meta-data pages (“auxiliary disk pages”) because they are more frequently accessed than client data pages.
Here’s one of the interesting performance results: “In the single-user (lightly loaded) case, WFS improved Woodstock’s average input response time over the local disk’s time for several reasons: WFS’s disks were faster than Woodstock’s local disks, requested pages were sometimes still in the WFS main memory cache, and the amount of arm motion on the local disk was reduced because it no longer had to seek between a code swap-area and the user data area.”
Accessing data over the network was faster than the local disk drive! Whether this is a statement of how slow disks were versus networks I leave as an exercise to the reader. One thing we can take away from this: the network often does not impose a significant bottleneck to utilizing remote storage (except, of course, when it does.)
The authors’ follow up their implementation description with an explanation of their design philosophy. They emphasize the atomic nature of the operations they support, as well as the following properties:
- Client initiated operations can only access one data page and “a few” auxiliary disk pages.
- Operations are persistent before WFS returns status to the client.
- WFS commands are a single internet packet.
- The WFS protocol is stateless.
They then explain the rationale for these decisions, which relate to simplifying the protocol and server side implementation.
They delve into how clients might use WFS in Section 4. One explicit take-away here is that they view these “files” as acting like “virtual disks” and this permits the WFS clients to implement their own abstraction on top of the WFS-provided services. Because WFS doesn’t assume any specific structure for the client data, there is no burden placed upon those client implementations – though they admit at one point that this complicates the client.
The authors are able to point to other systems that utlize WFS besides Woodstock. They cite to Paxton’s system (A Client-Based Transaction System to Maintain Data Integrity) as being based upon WFS.
The paper discusses security and privacy considerations, admitting their system does not address these issues and suggests various techniques to addressing security using encryption and capabilities. They round out this section of the paper by discussing other possible enhancements to WFS.
In the end, they provided a simple model for a network file server that permitted a client to implement a range of solutions. As we begin looking at more network file systems, we will see this model extended in various way.
A Universal File Server
A. D. Birrell and R. M. Needham, in IEEE Transactions on Software Engineering, Vol SE-6, No. 5, September 1980, pp. 450-453.
One of the challenges in this next group of papers is picking which ones to discuss. The advent of networks saw the blossoming of the idea of centralizing storage and having different computer systems accessing it via those networks. By the time this paper is published quite a few network based file server solutions had been constructed and described within the literature – and we will get to them.
The authors here decided to try and extract generality from these works. So in this paper we step back and look for some generality.
This is a rather short paper – four pages.
The authors describe the division of responsibilities in a file server: the “high-level functions more properly associated with a filing system” and “functions belonging to a backing store server” [emphasis in the original]. When I read this I thought that this made sense: we have a functional layer that creates a name space, attributes, etc. and a storage layer that keeps track of storage blocks.

By splitting out this functionality, the authors then suggest that the backing store server is a point of commonality that can be used to support a range of higher level services. Thus, “[t]he backing store server is the sole agency concerned with allocating and relinquishing space on the storage medium.” To achieve this goal the authors propose a universal system of indexes as shown in Figure 1 (from the original paper).
The authors argue for a master table that presents the per-system name space. For each of these namespaces, there is a corresponding master file directory (MFD) and a collection of user file directories (UFDs) that are used to organize the user’s information into a hierarchy.
We note that the files, UFDs and MFD are all stored in storage elements – segments – that are managed by the file server. Thus the file server is responsible for:
- Keeping track of its initial index
- Preserve the names stored in the MFD and UFDs
- Reclaim (delete) the entries in the MFD and UFDs when an entry is deleted
- Manage storage space
From this simple model, they note that a broad range of systems can be constructed.
The paper spends considerable (25% of the paper) time discussing “protection”. By this they refer to the issues inherent in having shared usage of a common resource, such as the files on the file server. The authors describe using ACLs on the file server as one means of providing security. They do not touch upon precisely how the file system will authenticate the users, though at one point they refer to using encryption for access bits in some circumstances.
Their preferred mechanism for access is the capability. This should not come as a surprise, given that they worked on the CAP file system, which provided capabilities. Their observation is that with a sufficiently sparse handle space, it is impractical for an unauthorized party to find the resource. It probably doesn’t require much to point out that this presumes the inherent integrity of the network itself.
The authors complete their universal file server with an observation that this provides a general base upon which individual file systems can implement their own enhanced functionality. Indeed, this was one of their primary objectives in doing this work. They do point out a number of potential issues in their system, but assert that they will not be problematic.
The authors do a good job of describing a basic, abstract file server. The system they describe may not have achieved broad use but this paper does provide a simple, high level view of how a file server might operate. We’ll turn our attention to actual implementations – and there are many such implementations to discuss in the coming posts.
Recent Comments