The Log-Structured Merge Tree
Patrick O’Neil, Edward Cheng, Dieter Gawlick, Elizabeth O’Neil in Acta Informatica, , Volume 33, Issue 4, pp 351–385.
This paper does not relate to non-volatile memory, but we will see Log-Structured Merge Trees (LSMTs) used in quite a few projects. From the abstract:
The log-structured mergetree (LSM-tree) is a disk-based data structure designed to provide low-cost indexing for a file experiencing a high rate of record inserts (and deletes) over an extended period. The LSM-tree uses an algorithm that defers and batches index changes, cascading the changes from a memory-based component through one or more disk components in an efficient manner reminiscent of merge sort. During this process all index values are continuously accessible to retrievals (aside from very short locking periods), either through the memory component or one of the disk components.
So LSMTs originate from concerns about the latency issues around disk drives.
In a nutshell, the challenge with disk drives are they have mechanical parts that must be moved in order to read the data. Data is written in concentric bands around the center. The angular velocity of the disk platter is the same, but of course the surface velocity is lowest towards the center and fastest towards the outer edge. The disk drive “head” is moved in and out to read from each of those concentric circles. Since it can only read what is beneath the head, it also must wait for the desired data to rotate under the head. This is one reason why faster disk drives (usually measured by the rotations-per-minute number) provide faster response times. On the other hand, faster disk drives generate more heat and are more expensive to build.
Thus, an important consideration for file systems working on rotating media is the latency to perform random access. Tape drives have the highest latency, since we have to reposition the tape to get to another location and read its data (there are other complexities as well, such as the fact that tape benefits most from streaming write). Hard disk drives (HDDs) are not so bad as tape drives in general (though SMR drives act much like tape drives, which is one reason I mention that here.) Solid State Disks are even better than disk drives, though even for an SSD random access is slower than sequential access – but both are much faster than HDDs.

Some of those papers that I have yet to cover describe the concept of a log-structured file system. One of the things that I learned when working on the Episode File System was that converting random I/O to sequential I/O was definitely a win (so was asynchronous logging). It is this observation: converting random I/O to synchronous I/O that provides the benefit of using journaling techniques (the “log”).

So LSMTs capitalize upon this advantage. Note that an LSMT is not a single data structure; rather it is a general technique for working with systems where insert and delete are the common operations, such as meta-data within a file system, or (key,value) tuples in a key-value store. It also points out that reading large sequential block is generally more efficient; they cite IBM when noting that a single page read from the DB2 Database takes approximately 10 milliseconds. A read of 64 continuous pages costs about 2 milliseconds per page (125ms total). So batching I/O operations is also an important mechanism for improving performance.
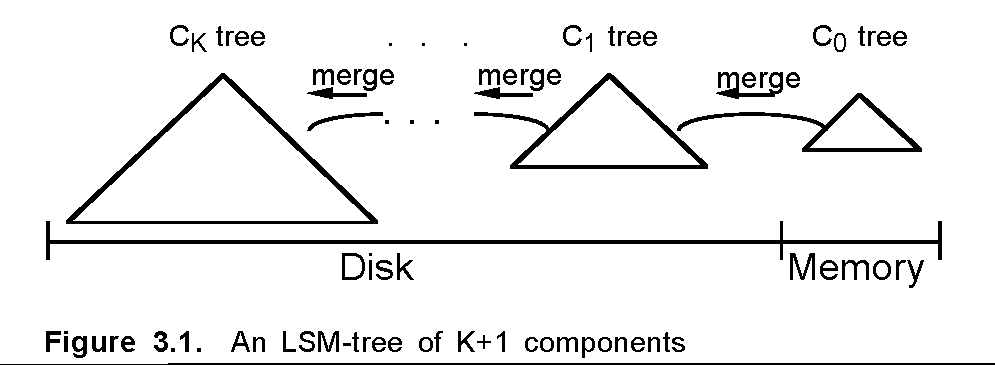
So what is an LSMT? “An LSM-tree is composed of two or more tree-like component data structures.” From there the authors describe their initial case: where one tree is memory resident and the other is disk resident. Note, however, this is the smallest set for a valid LSMT. Systems with more than two have been built – and one way to use non-volatile memory (NVM) is to add it as another layer to an LSMT.

Figure 2.1 (from the paper) shows the high level structure of the LSMT – a tree-like structure at each level of the storage hierarchy; these levels can have different characteristics, such as being ephemeral (in memory) or persistent (on disk, tape, SSD, etc.) Figure 2.2 provides greater detail, showing how data is merged from one level to the next (“rolling merge”). Figure 3.1 shows a generalization of the LSMT, in which data is migrated from one level of the storage hierarchy to the next.
Figure 6.1 then helps motivate this work: data that is seldom accessed (which is most of the data) is “cold” and can be stored in lower cost storage. Data that is frequently accessed (which is a small amount of the data) is “hot” and benefits from being stored in faster but more expensive storage. Indeed, there is a substantial body of work at this point that demonstrates how data tends to cycle from being hot to being cold. Thus, there is a period of migration for “warm” data. This also helps explain why having a multi-stage model makes sense. This behavior is quite general, in fact. Disk drives are constructed with caches on them. The cache is for the hot data, the disk storage for the cold data. SSDs are often structured with multiple classes of NVM; a small amount of expensive but fast NVM and then a larger amount of less expensive (often block oriented) NVM. Even CPUs work this way (as I will be discussing ad nauseum), where there are multiple levels of caching: L1 cache is small but very fast, L2 cache is larger and slower (and cheaper), L3 cache is again larger and slower. Then we get to memory (DRAM) which is even slower. That’s all before we get to storage!
This is quite a long paper: they describe how data is merged from one level to the next as well as do an in-depth analysis of cost versus performance. But I will leave ferreting out those details to the interested reader. I got what I came for: a basic description of the tiered nature of LSMTs and how we can use them to make storage more efficient without driving up costs.