As I mentioned in my last post, I am considering how to add activity context as a system service that can be useful in improving findings. Last month (December 2021) my examination committee asked me to consider a useful question: “If this service already existed what would you build using it?”
The challenge in answering this question was not finding examples, but rather finding examples that fit into the “this is a systems problem” box that I had been thinking about while framing my research proposal. It has now been a month and I realized at some point that I do not need to constrain myself to systems. From that, I was able to pull a number of examples that I had considered while writing my thesis proposal.
The first of this is likely what I would consider the closest to being “systems related.” This hearkens back to the original motivation for my research direction: I was taking Dr. David Joyner’s “Human-Computer Interaction” course at Georgia Tech and at one point he used the “file/folder” metaphor as an example of HCI. I had been wrestling with the problem of scope and finding and this simple presentation made it clear why we were not escaping the file/folder metaphor – it has been “good enough” for decades.
More recently, I have been working on figuring out better ways to encourage finding, and that is the original motivation for my thesis proposal. The key idea of “activity context” has potentially broader usage beyond building better search tools.
In my research I have learned that humans do not like to search unless they have no other option. Instead, they prefer to navigate. The research literature says that this is because searching creates more cognitive load for the human user than navigation does. I think of this as meaning that people prefer to be told where to go rather than being given a list of possible options.
Several years ago (pre-pandemic) Ashish Nair came and worked with us for nine weeks one summer. I worked with him to look at building tools to take existing file data across multiple distinct storage domains and present them based upon commonality. By clustering files according to both their meta-data and simply extracted semantic context, he was able to modify an existing graph data visualizer to permit browsing files based on those relationships, regardless of where they were actually stored. While simple, this demonstration has stuck with me.
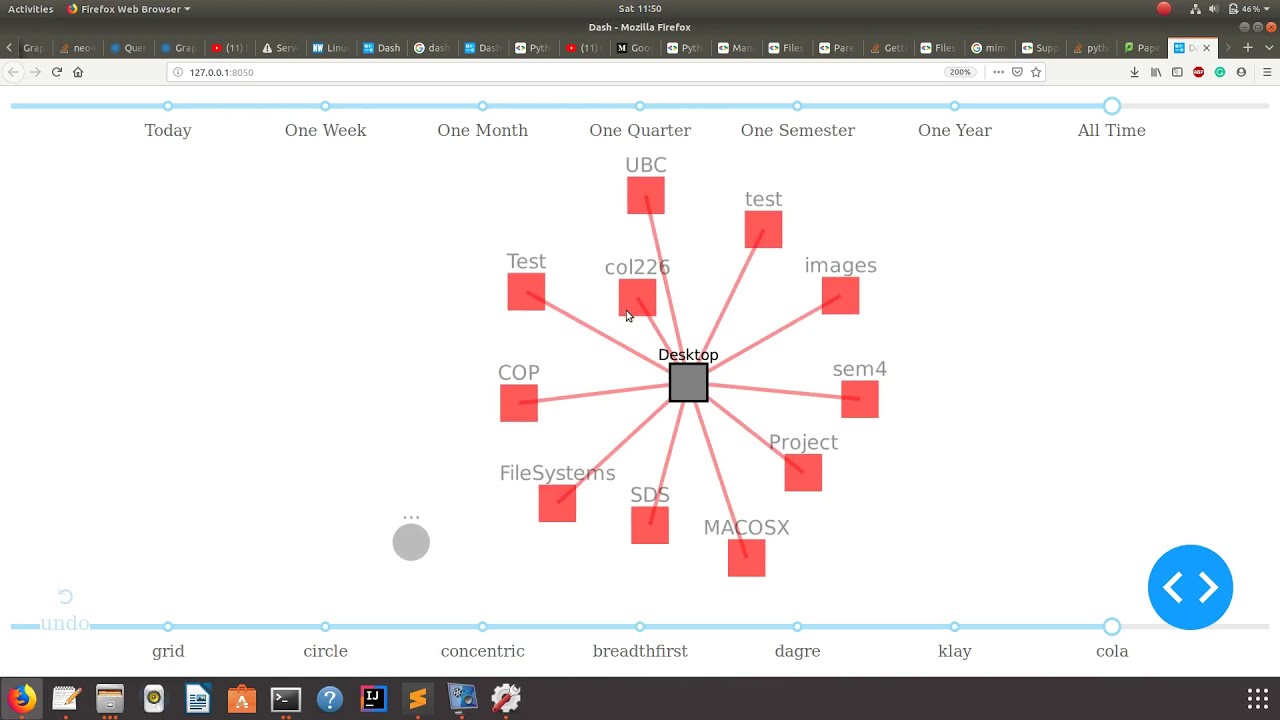
Thus, pushed to think of ways in which I would use Indaleko, my proposed activity context system, it occurred to me that using activity context to cluster related objects would be a natural way to exploit this information. This is also something easy to achieve. Unlike some of my other ideas, this is a tool that can demonstrate an associative model because “walking a graph” is an easy to understand way to walk related information.
There is a small body of research that has looked at similar interfaces. One that stuck in my mind was called Focus. While the authors were thinking of tabletop interfaces, the basic paradigm they describe, where one starts with a “primary file” (the focus) and then shows similar files (driven by content and meta-data) along the edges. This is remarkably like Ashish’s demo.
The exciting thing about having activity context is that it provides interesting new ways of associating files together: independent of location and clustered together by commonality. Both the demo and Focus use existing file meta-data and content similarity, which is useful. With activity context added as well, there is further information that can be used to both refine similar associations as well as cluster along a greater number of axis.
Thus, I can show off the benefits of Indaleko‘s activity context support by using a Focus-style file browser.
Seems like my brain initially had a difficult time breaking away from the traditional file system navigation (root -> nodes etc) — it’s so embedded in my mental model (as well as the day to day operations). However, after watching the YouTube video, I can understand why you want to explore this Focus-style file browser. This style of navigation adds context; I can anticipate that using the metadata and content similarity can be applied to AI assisted Personal Information Management (PIM). These days, I use a combination of content hierarchy and tags to organization my knowledge repository but can totally envision a future where these graphs are build in a way similar to that of Focus.
I agree with you: it is difficult to break away from a paradigm that we have been taught all of our lives. I remember listening to Dave Gifford talk about his semantic file system work in 1990 when I was at Transarc working on distributed file systems and thinking “this is crazy”. In the end, Gifford was right about extracting additional context, since modern indexers work by having content-aware plug-ins that extract semantic content. Tagging models are not new, and quite a few people have looked at various ways of tagging information. My observation is that asking human users to do so is a lost cause: almost nobody will. Similarly, there is zero incentive for people to delete stuff, so effective search becomes even more important. Google taught us how using relationships to improve search results is useful but files don’t have that sort of easily extracted cross-reference material. Looking at how files are used to infer relationships is helpful, as the provenance drive search research shows, but very recent work suggests that the things we do – our meetings, our e-mails, the websites we visit, how we are feeling – yields even more data that is contextually useful. However, to explore this we need to make it easy to use. While I suspect a better paradigm can replace the hierarchical data organization model of the file/folder world, I don’t think that will happen overnight. Fortunately, if done properly, they can co-exist with each other. When the non-hierarchical file browser becomes the preference of users over the classic file browser, it will replace it. I just want to explore enabling this option by having the system collect, store, and disseminate all of this meta-data, including inferred relationship information as well as semantically based information.