Home » Articles posted by Tony Mason (Page 5)
Author Archives: Tony Mason
Exploiting Hardware Transactional Memory in Main-Memory Databases
Viktor Leis, Alfons Kemper, Thomas Neumann in 2014 IEEE 30th International Conference on Data Engineering, pp 580-591.
I have not spent much time discussing transactional memory previously, though I have touched upon it in prior work. By the time this paper was presented, transactional memory had been fairly well explored from a more theoretical perspective. Intel hardware with transactional memory support was just starting to emerge around the time this paper was released. I would note that Intel had substantial challenges in getting hardware transactional memory (HTM) correct as they released and then pulled support for it in several different CPU releases. Note that HTM was not new, as it had been described in the literature to an extent that earlier papers (e.g., Virtualizing Transactional Memory, which I have decided not to write about further, discusses the limitations of HTM back in 2005).
Logically, it extends the functionality of the processor cache by tracking what is accessed by the processor (and driven by the program code). Cache lines are read from memory, any changed made to the cache line, and then written back to memory. This is in turn all managed by the cache coherency protocol, which provides a variety of levels of coherency.
The idea behind HTM is that sometimes you want to change more than a single element of memory. For example, you might use a mutual exclusion, then add something to a linked list, and increment a counter indicating how many elements are in the linked list before you release the mutual exclusion. Even if there is no contention for the lock, you will pay the lock cost. If the platform requires a fence operation (to ensure memory has been flushed properly) you will also stall while the memory is written back. In a surprising number of cases, you need to do multiple fences to ensure that operations are sequentially consistent (which is a very strong form of consistency).
With HTM you can do this all speculatively: start the transaction, add something to the linked list, increment the counter, then commit the transaction. Once this has been followed with an appropriate fence, the change is visible to all other CPUs in the system. The goal then is to avoid doing any memory operations unless absolutely necessary.

The authors point out that the fastest option is partitioning (ignoring hot spots). They graphically demonstrate this in Figure 1 (from the paper). HTM has some overhead, but it tracks with partitioning fairly linearly. This difference is the overhead of HTM.
They compare this to serial execution, which just means performing them one at a time. The traditional mechanism for doing this kind of paralleism is the two phase commit protocol. That’s the lock/work/unlock paradigm.
If we only considered this diagram, we’d stick with strong partitioning – and we’re going to see this observation reflected again in future work. Of course the reason we don’t do this is because it turns out that the database (and it shows up in file systems as well) is not being uniformly accessed. Instead, we have hot spots. This was a particular concern in the MassTree paper, where they supported novel data structures to spread the load around in a rather interesting fashion. There’s quite a bit of discussion about this problem in the current paper – “[A] good partitioning scheme is often hard to find, in particular when workloads may shift over time.” Thus, their observation is: “we have to deal with this problem”.
 So, how can HTM be exploited to provide robust scalability without partitioning. The authors do a good job of explaining how HTM works on Intel platforms. Figure 4 (from the paper) shows a fairly standard description of how this is done on the Intel platform: it has a bus snooping cache, an on-chip memory management unit (MMU), a shared Level 3 cache, and per core Level 1 and Level 2 caches (in case you are interested, the two caches do have somewhat different roles and characteristics.) Level 1 cache is the fastest to access, but the most expensive to provide. Level 2 cache is slower than Level 1, but because it is also cheaper we can have more of it on the CPU. Level 3 cache might be present on the CPU, in which case it is shared between all three cores. Note that none of this is required. It just happens to be how CPUs are constructed now.
So, how can HTM be exploited to provide robust scalability without partitioning. The authors do a good job of explaining how HTM works on Intel platforms. Figure 4 (from the paper) shows a fairly standard description of how this is done on the Intel platform: it has a bus snooping cache, an on-chip memory management unit (MMU), a shared Level 3 cache, and per core Level 1 and Level 2 caches (in case you are interested, the two caches do have somewhat different roles and characteristics.) Level 1 cache is the fastest to access, but the most expensive to provide. Level 2 cache is slower than Level 1, but because it is also cheaper we can have more of it on the CPU. Level 3 cache might be present on the CPU, in which case it is shared between all three cores. Note that none of this is required. It just happens to be how CPUs are constructed now.
 The benefit of HTM then is that it exploits the cache in an interesting new way. Changes that are made inside a transaction are pinned inside the cache so they are not visible outside the current core. Note, however, that this could mean just the L1 cache. In fact, the functional size permitted is even smaller than that, as shown in Figure 5 (from the paper). Transactions below 8KB have a low probability of aborting (and if it aborts, the operation failed so it must be tried again, either using HTM or the fallback mechanism with software). That probability approaches 100% as the size goes above above 8KB. Interestingly, the primary reason for this is not so much the size of the cache as the associativity of the cache. What that means is the cache uses some bits from the address to figure out where to store data from that particular cache line. The paper points out that 6 bits (7-12) are used for determining the cache location, and each cache location (so each unique value of bits 7 through 12) are has a fixed number of cache lines (e.g., 8 entries in the Haswell chips the authors are evaluating). If we need to use a ninth we evict one of the existing pages in the cache.
The benefit of HTM then is that it exploits the cache in an interesting new way. Changes that are made inside a transaction are pinned inside the cache so they are not visible outside the current core. Note, however, that this could mean just the L1 cache. In fact, the functional size permitted is even smaller than that, as shown in Figure 5 (from the paper). Transactions below 8KB have a low probability of aborting (and if it aborts, the operation failed so it must be tried again, either using HTM or the fallback mechanism with software). That probability approaches 100% as the size goes above above 8KB. Interestingly, the primary reason for this is not so much the size of the cache as the associativity of the cache. What that means is the cache uses some bits from the address to figure out where to store data from that particular cache line. The paper points out that 6 bits (7-12) are used for determining the cache location, and each cache location (so each unique value of bits 7 through 12) are has a fixed number of cache lines (e.g., 8 entries in the Haswell chips the authors are evaluating). If we need to use a ninth we evict one of the existing pages in the cache.
Similarly, when the duration of the transaction goes up, the probability of it aborting also rises. This is shown in Figure 6 (from the paper). This is because the chance that various systems events will occur, which cause the transaction to abort. This includes various types of interrupts: hardware and software.
 Thus, these two graphically demonstrate that to exploit HTM effectively we need to keep our transactions small in both duration and the number of cache lines modified by them.
Thus, these two graphically demonstrate that to exploit HTM effectively we need to keep our transactions small in both duration and the number of cache lines modified by them. 
We also note that we should take steps to minimize the amount of sharing of data structures that might be required – the point that not sharing things is more efficient. The authors discuss a variety of approaches to this issue: segmenting data structures, removing unnecessary conflict points (e.g., counters), and appropriate choice of data structures.
Recall the Trie structures from MassTree? These authors offer us Adaptive Radix Trees, which seem to have a similar goal: they are “[A]n efficient ordered indexing structure for main memory databases.” They combine this with a spin lock; the benefit now is that HTM doesn’t require the spin lock normally, so even if some parts of the tree are being read shared, the lock is not being acquired and thus it does not force a transactional abort for other (unrelated) nodes.

They put all of this insight together and that forms the basis for their evaluation. Figure 11 in the paper makes the point that HTM scales much better than traditional locking for small lookups (4 byte keys) with a uniform distribution once there is more than one thread.
Figure 12 (from the paper) evaluates the TPC-C Benchmark against their resulting system to demonstrate that it scales well . Note they stick with four threads, which are all likely on a single physical CPU, so there are no NUMA considerations in this aspect of the evaluation. They address this a bit later in the paper.

Figure 13 (from the paper) compares their performance against a partitioned system. Because they cannot prevent such cross-partition access, they must “live with” the inherent slowdown. One of the amazing benefits of HTM is thus revealed: as more operations cross partition boundaries, HTM continues to provide a constant performance. This seems to be one of the key lessons: no sharing is great, but once you find that you must share, synchronizing optimistically works surprisingly well.
 Figure 14 (from the paper) attempts to address my comment earlier abut Figure 12: they really don’t have a multiprocessor system under evaluation. They admit as much in the paper: the hardware just isn’t available to them. They provide their simulation results to defend their contention that this does continue to scale, projecting almost 800,000 transactions per second with 32 cores.
Figure 14 (from the paper) attempts to address my comment earlier abut Figure 12: they really don’t have a multiprocessor system under evaluation. They admit as much in the paper: the hardware just isn’t available to them. They provide their simulation results to defend their contention that this does continue to scale, projecting almost 800,000 transactions per second with 32 cores.
 Figure 15 (from the paper) finally demonstrates the reproducibility of HTM abort operations. If an HTM is retried, many will complete with one or two tries. Thus, it seems that even with multiple threads, they tend to converge towards the hardware limitations.
Figure 15 (from the paper) finally demonstrates the reproducibility of HTM abort operations. If an HTM is retried, many will complete with one or two tries. Thus, it seems that even with multiple threads, they tend to converge towards the hardware limitations.
Bottom line: hardware transactional memory can be a key aspect of improving performance in a shared memory systems with classical synchronization.
SILT: A Memory-Efficient, High-Performance Key-Value Store
Hyeontaek Lim, Bin Fan, David G. Andersen, Michael Kaminsky, in Proceedings of the 23rd Symposium on Operating Systems Principles (SOSP ’11), October 23-26, 2011, Cascais, Portugal.
In this paper, we have an interesting hybrid key-value store; part of the store is in DRAM, while the rest of it is stored in flash storage. The authors have focused on optimizing the performance of the store across the specific media chosen, which leads to some interesting choices and observations.
SILT (Small Index Large Table) is a memory-efficient, highperformance
key-value store system based on flash storage that
scales to serve billions of key-value items on a single node. It requires
only 0.7 bytes of DRAM per entry and retrieves key/value
pairs using on average 1.01 flash reads each. SILT combines new
algorithmic and systems techniques to balance the use of memory,
storage, and computation. Our contributions include: (1) the design
of three basic key-value stores each with a different emphasis on
memory-efficiency and write-friendliness; (2) synthesis of the basic
key-value stores to build a SILT key-value store system; and (3) an
analytical model for tuning system parameters carefully to meet the
needs of different workloads. SILT requires one to two orders of
magnitude less memory to provide comparable throughput to current
high-performance key-value systems on a commodity desktop
system with flash storage.
Thus, to achieve optimal performance they construct a hybrid ensemble of key-value stores that are optimized to particular underlying media.
They start early with their performance observations, and continue this pace throughout the paper. Thus, they point out that they have a small memory requirement (0.7 bytes per key value) and only a single read from flash required:
 This fits well with their observation that memory efficiency is critically important for scalable key-value stores. Their system saturated the capabilities of their hardware with 46,000 lookups per second, though this doesn’t guarantee that it will do so on newer, faster hardware (and we will get to several current KV stores.
This fits well with their observation that memory efficiency is critically important for scalable key-value stores. Their system saturated the capabilities of their hardware with 46,000 lookups per second, though this doesn’t guarantee that it will do so on newer, faster hardware (and we will get to several current KV stores.
 Figure 2 (from the paper) provides a basic description of the SILT architecture. From this, we can see the three distinct types of stores that are used within their implementation:
Figure 2 (from the paper) provides a basic description of the SILT architecture. From this, we can see the three distinct types of stores that are used within their implementation:
- LogStore – uses a CPU-efficient cuckoo-hash based only upon a tag derived from the full key (20 bytes). The benefit of this approach is that it avoids accessing the flash memory if the key is not present. It is probabilistic, in that a key might not be present in Flash with some low probability.
- HashStore – uses a memory-efficient storage model for their cuckoo flash table. These stores are immutable and are stored in flash.
- SortedStore – They use an entropy-coded trie, which provides a very space efficient indexing mechanism: the average according to the authors is 0.4 bytes per key. Given that keys are 160 bits (20 bytes), which means the index is 64 bits (8 bytes). The authors provide us with an impressive list of specific optimizations they have applied to sorting data, packing indexes, intelligent (non-pointer) based addressing,
They also provide us with pretty figures to graphically lay out their data structures. First, Figure 3, which shows the in-memory cuckoo hash table:
 Note the fact the key-value insertions are logged to the flash storage.
Note the fact the key-value insertions are logged to the flash storage.
When we move onto HashStore, they show us how the structure of the data is moved from insertion order to hash sorted order as the data is moved from memory to flash.
 Recall that once written to Flash, the HashStore is immutable – so this order will remain fixed.
Recall that once written to Flash, the HashStore is immutable – so this order will remain fixed.
Of course, one of the important aspects of a key-value store is the ability to look up the data quickly. Thus, they also show us how they sort data using a prefix tree (Trie). This is a key aspect of their SortedStore:

The in-memory Trie, permits them to rapidly find the corresponding data in Flash. This is one of their key motivations for very efficient encoding of the Trie: it ensures they can store it in memory. Once they can no longer store the indices in memory the lookup system will become I/O bound (to the Flash, in this case).
Figure 6 then shows how they actually encode the length of the tree in each direction, and how it is entropy encoded: There is some serious thought that has gone into their layout. They do admit, however, that they are not providing crash tolerance: there will be data that was stored in DRAM that cannot be recovered after a crash. They do not discuss the use of NVM for achieving this. Instead, they suggest a synchronous write mechanism in which the write blocks until the log data has been written to the flash-based log.
There is some serious thought that has gone into their layout. They do admit, however, that they are not providing crash tolerance: there will be data that was stored in DRAM that cannot be recovered after a crash. They do not discuss the use of NVM for achieving this. Instead, they suggest a synchronous write mechanism in which the write blocks until the log data has been written to the flash-based log.
One of the interesting aspects of their performance evaluation is the recognition that they have quite a few parameters that must be chosen. Thus, they spend more than a page of the paper just discussing the relative merits of the trade-offs involved in selecting various parameters. They consider write amplification (the need to write more than just the data being preserved), read amplification (performing reads only to discover the data that you seek is not present), memory overhead (how much DRAM is used), and update rate versus flash life time. This latter point is an interesting one to keep in mind when reading about non-volatile memory: it wears out. There is a certain amount of degradation that occurs in the underlying physical medium each time it is erased and re-used. The specific details are dependent upon the characteristics of the medium, but it is an issue to keep in mind.
The evaluation of SILT is certainly interesting. They choose not to compare to any other KV system and instead focus on the performance of their system using a variety of fairly standard loads (YCSB) as well as simple get/put key operations as micro-benchmarks. They end up claiming they they can lookup almost 45k keys per second in the slowest of their hybrid stores. When combined, they indicate they can achieve almost 58k get operations per second on a single core. As they move to multiple cores they see some further improvement (180k get operations per second for data that is already in memory).
SILT offers some interesting observations, particularly about highly efficient use of memory and novel indexing schemes.
Logic and Lattices for Distributed Programming
Neil Conway, William R. Marczak, Peter Alvaro, Joseph M. Hellerstein, and David Maier, in Symposium on Cloud Computing 2012 (SOCC ’12), October 14-17, 2012, San Jose, CA.
This is definitely a different direction than we’ve had in prior papers, though I do have an ulterior motive in presenting this particular paper – we will see it used later.
In recent years there has been interest in achieving application-level
consistency criteria without the latency and availability costs of
strongly consistent storage infrastructure. A standard technique is to
adopt a vocabulary of commutative operations; this avoids the risk
of inconsistency due to message reordering. Another approach was
recently captured by the CALM theorem, which proves that logically
monotonic programs are guaranteed to be eventually consistent. In
logic languages such as Bloom, CALM analysis can automatically
verify that programs achieve consistency without coordination.
In this paper we present BloomL, an extension to Bloom that
takes inspiration from both of these traditions. BloomL generalizes
Bloom to support lattices and extends the power of CALM analysis
to whole programs containing arbitrary lattices. We show how the
Bloom interpreter can be generalized to support ecient evaluation
of lattice-based code using well-known strategies from logic
programming. Finally, we use BloomL to develop several practical
distributed programs, including a key-value store similar to Amazon
Dynamo, and show how BloomL encourages the safe composition
of small, easy-to-analyze lattices into larger programs.
Notice they do mention key-value stores, so you have another hint on how I’ll be referring back to this work in a future post.
This tends more to the theoretical side of systems. It is not a theory paper (there just isn’t enough formalism, let alone proofs!) It has performance graphs, which you certainly expect from a systems paper, but not from a theory paper.
The driving factor behind this is the issue of distributed consistency. At a high level, “distributed consistency” is concerned with ensuring that a group of communicating computers, with some temporal separation, agree on the outcome of operations even when things go wrong. Perhaps the most famous example of distributed consistency is Paxos. These days we refer to these as consensus protocols. I generally describe there being several such: two-phase commit is certainly one of the older ones. Quorum protocols are another (e.g., weighted voting, which I described previously). Viewstamped Replication is another. These days, the popular consensus protocols are
Raft and Blockchain.

The paper starts by pointing out that monotonic consisency provides a valuable mechanism for reasoning about distributed consistency. Prior work by the authors establishes that all monotonic programs are “invariant to message reordering and retry”, a property they call confluent. This matters for distributed systems because such a system only moves forward (the operations are durable.)
They point out some weaknesses in the prior definition and motivate improving it by explaining one such obvious case that does not fit within the model (a voting quorum in a distributed protocol.)
Hence, they introduce the lattice. They do this within the context of their language (BloomL), which works on top of Ruby. I will not dwell on the details.
The authors define a bounded semijoined lattice. My reading of what they are saying is that in such a set, there is a unique element that happened first. They define this formally as a set S, with an operator (“bottom” that I don’t seem to have in my font set) that defines a partial ordering. There is a unique element ⊥ that represents the least element.
From this definition, they construct their model; the paper drops the “bounded semijoined” part of the definition and simply discusses lattices from that point forward, but it is this partial ordering property that imparts the key characteristics to their subsequent operations.
Why is this important? Because it demonstrates that these lattices – which are going to turn out to be equivalent to key operations in distributed systems – have consistency guarantees that are desirable.
The authors then turn their attention to utilizing lattices for key-value stores. They describe data structure versioning and vector clocks. Vector clocks have a property they desire for lattices: they are partially ordered. They combine this with a quorum voting protocol, to provide the distributed consensus for their system.

Figure 8 (from the paper) shows the general structure of their key-value store implementation, which is implemented in BloomL and Ruby. Their sample usage for this is a shopping cart, which they graphically describe in Figure 9 (from the paper).
As one would expect in a distributed system, the key benefit here is that there is no centralized authority deciding on the order of things. They point out that prior work argues shopping carts are non-monotonic and thus cannot be solved in a distributed systems setting. The authors point out that using the lattice structure, they achieve a monotonic ordering, which permits them to implement it without a centralized decision maker; in fact the decision maker in this case is really the client itself, as it has all the information from all the servers sufficient to complete the operation.
While a shopping cart might not be the killer application for a distributed systems technology, this paper does describe a powerful tool for providing distributed consensus in a system that can be implemented in a modest amount of code; compared to Paxos, Raft, or Viewstamped Replication, that is a significant contribution.
It does not appear to have byzantine protection, however, so if you live in a hostile environment it might not be the right protocol. Similarly, if you need stronger consistency guarantees, this might not be the best model either. But for many applications slightly relaxed consistency guarantees are often more than adequate.
We will see how this can be applied in the future.
Cache Craftiness for Fast Multicore Key-Value Storage
Yandong Mao, Eddie Kohler, Robert Morris, in Proceedings of the 7th ACM european conference on Computer Systems (Eurosys ’12), pp. 183-196, Bern, Switzerland, April 10 – 13, 2012.
In this work, the authors build a key-value system called MassTree. This is an in-memory Key-Value store (I will look at several of them, in fact). What is novel about this particular variant is the authors focus on providing a high-performance parallel access implementation and the mechanisms by which they achieve this.

MassTree support arbitrary-length keys; it assumes nothing about the keys (so they may be binary data). It uses B+-trees for storage organized into a Trie structure. The B+-tree stores a fixed slice of the key; the Trie connects the various slices together. This use is interesting, since most of the cases I’ve seen of Tries are for strings, as they do an excellent job of managing overlapping string data (prefix trees). The authors use this for binary keys. There is nothing inherently more difficult about binary versus string keys (since they are equivalent) but this choice makes the solution very flexible, as it is not particularly data dependent. This basic layout is shown in Figure 1 (from the paper).
One of the challenges with concurrent data structures is how to handle the common case – no collisions – with minimal performance overhead. The classic mutual exclusion model (or reader/writer locks) involves a certain amount of overhead, even for non-contended locks, because of the need to perform interlocked operations against shared (common) memory where the locks are maintained. The system implemented by the authors does not require any locking for readers (lookups). Updates are done with locks local to the CPU, which helps minimize the contention of typical locks.
One interesting observation is that their choice of this hybrid Trie/B+-tree structure was motivated by prior systems that struggled with performance in the presence of variable length keys. In MassTree, the rate limiting factor for queries is the cost of walking the tree. They minimize this by using “a wide fan-out tree to reduce tree-depth, prefetches nodes from DRAM to overlap fetch latencies, and carefully lays out data in cache lines to reduce the amount of data needed per node.”
Hence, my interest in this paper: these all seem to be important lessons for persistent memory as well, where the latencies are somewhat larger than for DRAM. Further, the authors are concerned about correctness. They have not looked at persistence (and recoverable consistency), so there is still further work for me to do should I investigate it further.
The authors conclude by claiming the following contributions:
First, an in-memory concurrent tree that supports keys with shared prefixes efficiently. Second, a set of techniques for laying out the data of each tree node, and accessing it, that reduces the time spent waiting for DRAM while descending the tree. Third, a demonstration that a single tree shared among multiple cores can provide higher performance than a partitioned design for some workloads. Fourth, a complete design that addresses all bottlenecks in the way of million-query-per-second performance.
Their emphasis on correctness and cache efficiency is certainly an attractive aspect of this work.
The driving considerations for their design were: efficient support of many different key distributions including binary and variable length keys, with common prefixes; fine grained concurrent access for high performance parallel access, and cache efficiency through optimal data placement and prefetching.
The authors establish the characteristics of their tree structure, including data placement. These make reasoning about their tree characteristics simpler. For example, they note that MassTree does not guarantee that it is a balanced structure. However, due to the way the tree itself is structured, they have the same algorithmic cost: O(l log n) comparisions, where l is the length of the key and n is the depth of the tree.
As a pragmatic check on their implementation, they also use a partial-key B-tree (pkB-Tree) for comparison. Despite the fact the pkB-Tree is balanced, the authors note that MassTree performs favorably well on several benchmarks. The authors go into detail about their implementation details, including the construction of border nodes and interior nodes, as well as how they lay out data (again, with an eye towards cache line efficiency).
 To achieve this efficiently, they use a versioning scheme. A node has a version number. To modify the node, a given processor must update the version to indicate that it is changing the node. A reader will snapshot the version at the start of the read, and compare it at the end of the read. If it changed, the reader knows the state may have changed and can retry the read operation (essentially a variant of software transactional memory). The detailed diagram of this is shown in Figure 3 (from the paper).
To achieve this efficiently, they use a versioning scheme. A node has a version number. To modify the node, a given processor must update the version to indicate that it is changing the node. A reader will snapshot the version at the start of the read, and compare it at the end of the read. If it changed, the reader knows the state may have changed and can retry the read operation (essentially a variant of software transactional memory). The detailed diagram of this is shown in Figure 3 (from the paper).
The paper describes the concurrency model in the face of conflicting writers as well. By keeping their lock in the same cache line as their data, they exploit the cache coherence protocol. The authors note that lock-free operations have comparable cache behavior (e.g., compare-and-swap or link-load-store-conditional).
 Indeed, much of the rest of the technical content of the paper is explaining why their approach is correct – an essential point for concurrent access systems. Without that, there really is not much point!
Indeed, much of the rest of the technical content of the paper is explaining why their approach is correct – an essential point for concurrent access systems. Without that, there really is not much point!
While brief, their discussion about value storage is interesting: their measurements are done assuming that values will be small. They state they have a scheme for managing large values as well, via a separate allocator. While they do not claim this, my observation is that a “real world” system would likely need to have some hybrid form of this.
MassTree is an in-memory key-value store. To provide persistence, they rely upon a write-behind log scheme. When used via the network interface, the writes are not guaranteed. To minimize the loss window, they choose a 200 ms timer. Thus, the log is written to disk every 200 ms. They do not evaluate this persistence model, offering it to us as an explanation that persistence is not incompatible with performance.
This last point is an interesting one, especially when considered in the context of NVM: what are the trade-offs. The authors hint at this, but do not explore this space.
For those interested, a version of the source code can be found here: https://github.com/kohler/masstree-beta
MRAMFS: A compressing file system for non-volatile RAM
Nathan K. Edel, Deepa Tuteja, Ethan L. Miller, and Scott A. Brandt in Proceedings of the 12th IEEE/ACM International Symposium on Modeling, Analysis, and Simulation of Computer and Telecommunication Systems (MASCOTS 2004), Volendam, Netherlands, October 2004.
This paper allows me to provide both a file systems paper and look at an interesting approach to byte-addressable non-volatile memory (NVM).
We have developed a prototype in-memory file system which utilizes data compression on inodes, and which has preliminary support for compression of file blocks. Our file system, mramfs, is also based on data structures tuned for storage efficiency in non-volatile memory.
One of the interesting aspects of NVM is that it has characteristics of storage (persistence) and memory (byte-addressability). Storage people are used to having vast amounts of time to do things: it is quite difficult, though not impossible, to do anything computationally with data that will be an important factor when it is combined with the overhead of I/O latency to disk drives. In-memory algorithms worry about optimal cache line usage and efficient usage of the processor, but they don’t need to worry about what happens when the power goes off.
Bringing these two things together requires re-thinking things. NVM isn’t as fast as DRAM. Storage people aren’t used to worrying about CPU cache effects on data resilience.
So mramfs looks at this from a very file systems centric perspective: how do we exploit this nifty new memory to build a new kind of RAM disk: it’s still RAM but now it’s persistent. NVRAM is slower than DIMM and hence it makes sense to compress it to increase the effective data transfer rate (though it is not clear if that really will be the case.)
I didn’t find a strong motivation for compression, though I can see the viability of it now, in a world in which we want to pack as much as we can into a 64 byte cache line. The authors point out that one of the previous systems (Conquest) settled on a 53 byte inode size. The authors studied existing systems and found they could actually compress down to 20 bytes (or less) for a single inode. They achieved this using a combination of gamma compression and compressing common file patterns (mode, uid, and gid). Another reason for this approach is they did not wish to burden their file system with a computationally expensive compression scheme.
 In Figure 1 (from the paper) the authors provide a graphic description of their data structures. This depicts a fairly traditional UNIX style file system, with an inode table, name space (directories), references from directory entries to the inodes. Inodes then point to control structures that eventually map to the actual data blocks.
In Figure 1 (from the paper) the authors provide a graphic description of their data structures. This depicts a fairly traditional UNIX style file system, with an inode table, name space (directories), references from directory entries to the inodes. Inodes then point to control structures that eventually map to the actual data blocks.
The actual memory is managed by the file system from a single chunk of non-volatile memory; the memory is virtually addressed and the paper points out that they don’t actually care how that mapping is achieved.
Multiple inodes are allocated together in inode blocks with each block consisting of 16 (variable length) inodes. The minimum size of a block is 256 bytes. inodes are rewritten in place whenever possible, which can lead to slack space. If an inode doesn’t fit within its existing space, the entire block is reconstructed and then written to a new block. Aftewards, the block pointer is changed to point to the new block. Then the old block is freed.
One thing that is missing from this is much reasoning about crash consistency, which surprised me.
The authors have an extensive evaluation section, comparing to ext2fs, ramfs, and jffs2 (all over RAM disk). Their test was a create/unlink micro-benchmark, thus optimizing the meta-data insertion/deletion case. They then questioned their entire testing mechanism by pointing out that the time was also comparable to what they achieved using tmpfs building the openssl package from source. Their final evaluation was done without the compression code enabled (“[U]nfortuantely, the data compression code is not yet reliable enough to complete significant runs of Postmark or of large builds…”). They said they were getting about 20-25% of the speed without compression.
Despite this finding, their conclusion was “We have shown that both metadata and file data blocks are highly compressisble with little increase in code complexity. By using tuned compression techniques, we can save more than 60% of the inode space required by previous NVRAM file systems, and with little impact on performance.”
My take-away? This was an early implementation of a file system on NVM. It demonstrates one of the risks of thinking too much in file systems terms. We’ll definitely have to do better.
Consistent and Durable Data Structures for Non-Volatile Byte-Addressable Memory
Shivaram Venkataraman, Niraj Tolia, Parthasarathy Ranganathan, and Roy H. Campbell in Proceedings of File Systems and Storage Technology 2011, Volume 11, pp 61-75, USENIX.
In this paper the authors turn their attention to data structure considerations for Non-Volatile Memory (NVM). Unlike the previous papers I have covered (Mnemosyne and NV-Heaps) they look at data structures specifically optimized to exploit the capabilities of NVM. From the abstract:
For these systems, where no distinction is made between a volatile and a persistent copy of data, we present Consistent and Durable Data Structures (CDDSs) that, on current hardware, allows programmers to safely exploit the low-latency and non-volatile aspects of new memory technologies. CDDSs use versioning to allow atomic updates without requiring logging.
Some other aspects of this paper that stand out:
- They are looking at NVM replacing both DRAM and storage – thus, they view this as a single level store.
- They use versioning to protect their data structures, versus logging.
- They describe how to achieve this without hardware changes.
 The paper has a good review of NVM memory technologies that may emerge. Table 1 (from the paper) underscores the dramatic decrease in latency. This is why we’ve been waiting for this for more than 10 years now. It really does change the platform in ways that we have not yet realized.
The paper has a good review of NVM memory technologies that may emerge. Table 1 (from the paper) underscores the dramatic decrease in latency. This is why we’ve been waiting for this for more than 10 years now. It really does change the platform in ways that we have not yet realized.
But it is not just the speed aspect that matters, it is also the persistence aspect. The density is much larger for these memories as well. Anyone that has looked at an NVMe M.2 drive can notice how few and small the components on it.
Do we treat it as storage? If so, perhaps we should look to the file systems world for some insight. The authors turn to the WAFL shadow page mechanism. They point to BTRFS and their use of this technique with B-trees. They dismiss this approach, concluding that they have “fewer data-copies” in CDDS. They distinguish this work because it is byte addressable versus prior work that was block oriented (page addressable). Again, the lessons learned from working with it aren’t directly applicable. They do point out that using NVM makes sense in a world of large, persistent storage backed data farms. So there is a need, and one they see fulfilled by NVM. It just needs efficient use of that NVM.
Thus, the authors walk their own path.
 The speed of NVM is such that direct access is the only mechanism that makes sense. System calls impose too much overhead, doubling the cost of accessing the NVM itself. Thus they posit that it will be direct access (and indeed that is what seems to come to pass).
The speed of NVM is such that direct access is the only mechanism that makes sense. System calls impose too much overhead, doubling the cost of accessing the NVM itself. Thus they posit that it will be direct access (and indeed that is what seems to come to pass).
They observe that one of the challenges for persistent data is that CPUs do not provide mechanisms for ordering persistent writes (though they do, but at a fairly coarse granularity of a fence.) So they describe the issues that must be handled:
- Reordering of writes from the caching behavior of the CPU itself as well as a multi-level cache hierarchy.
- Failure semantics of atomic operations across power failures.
They summarize the various approaches available to them for ensuring data has been stored properly in NVM. This includes memory fences, cache writeback and invalidate operations, marking memory as non-cacheable (which forces write-back), cache line flushes, and atomic processor operations. They point out that this is not sufficient for more complex updates, such as tree rebalancing operation. This leads them to versioning.
I found it interesting that their goals were similar to those I have seen previously: durability, consistency, scalability, and ease-of-use for the programmer. They also note that they focus on physical consistency of the data contents in memory. Logical consistency of higher level meta-data structures is not addressed in the context of this work.
Thus, the authors point out that a CDDS is an abstract idea; they demonstrate how they envision using it by implementing a b-tree structure (Figure 1 is from the paper as they describe their B-tree).
In versioning, changes are not made in place to the current version; instead, a new version is written. The current version is immutable (at least as long as it is the current version). Atomic operation and copy-on-write techniques are used to make changes persistent. Once done, a new version number is assigned and the new version becomes the current version. The old version can be recycled once its reference count drops to zero.
Failure recovery then becomes a function of “cleaning up” any in-progress operations that had not been written to disk.
The authors then walk through their B-tree example. They explain their use of versioning, they provide pseudo-code for the various B-tree operations (lookup, insert, delete) as well as the internal operations needed to support them.
They evaluate their solution by simulating NVM on top of DRAM (a common solution as we have seen). They compare against BerkeleyDB, STX B-Tree, Tembo, Cassandra, and Redis. They were slower than the entirely in-memory STX B-Tree, presumably due to the cost overhead. They are much faster than BerkeleyDB (even BerkeleyDB runing on a RAM disk.) They also tested using YCSB as their “end to end” benchmark.
In the end, they do demonstrate that it is possible to rebuild existing data structures – preserving the interface – so they work efficiently with NVM. They even point out it does not require processor changes to do so. Given that better processor cache control mechanisms have been introduced since then, I would expect that exploiting them will lead to even better performance.
NV-Heaps: Making Persistent Objects Fast and Safe with Next-Generation, Non-Volatile Memories
Joel Coburn, Adrian M. Caulfield, Ameen Akel, Laura M. Grupp, Rajesh K. Gupta, Ranjit Jhala, Steven Swanson
in ASPLOS XVI Proceedings of the sixteenth international conference on Architectural support for programming languages and operating systems, Pages 105-118, March 5-11, 2011.
This paper was presented at the same conference as Mnemosyne. The authors explore a different use of Non-Volatile Memory (NVM): using it for storing persistent objects. The authors sum up the motivation for this:
Creating these data structures requires a system that is lightweight enough to expose the performance of the underlying memories but also ensures safety in the presence of application and system failures by avoiding familiar bugs such as dangling pointers, multiple free()s, and locking errors. In addition, the system must prevent new types of hard-to-find pointer safety bugs that only arise with persistent objects. These bugs are especially dangerous since any corruption they cause will be permanent.
Thus, their motivation is to enable the use of these nifty “persistent, user-defined objects” that are not practical when backed by disks (“[T]he slow speed of persistent storage (i.e., disk) has restricted their design and limited their performance.”)

The authors make some important observations that are just as applicable today as they were in 2011. These include the observation that persistent objects in NVM cannot reasonably be treated like disk based objects “… because the gap between memory and storage performance drove many design decisions that shaped them.” Nor can they be treated like volatile memory: “To guarantee consistency and durability, non-volatile structures must meet a host of challenges, many of which do not exist for volatile memories.”
They also observe that NVMs greatly expand the possibility of bug sources from having disparate address spaces. In other words, while you have a single address space, part of it is ephemeral and if you store a reference to the ephemeral part in the persistent part, it will be inconsistent after the current process terminates.
I found their observation about the ability of programmers to reason about this also apropos: “[t]rusting the average programmer
to “get it right” in meeting these challenges is both unreasonable…” This is consistent with more than 50 years of experience in systems. Personally, I don’t think this is an indictment of the programmer so much as it is a burden on the system (a perspective the authors appear to endorse as well). To make this viable, we need to make it easy to get it right.
Figure 1 shows the general architecture of NV-Heaps: It is envisioned as a library of useful services layered on top of the operating system provided abstractions. One important observation here is that this model completely avoids the need to interact with the operating system in ordinary program execution. Persistence no longer relies upon utilizing the standard file systems interface.
The authors’ explanation of their goals looks like a veritable “wish list” to me: prevent programmer errors, transactions, referential integrity, performance and scalability, and ease of use. I’m not sure how referential integrity is different than programmer errors, but clearly it is a very important aspect of their persistent system.
 Figure 3 shows how they handle one of the complex consistency cases inherent in managing NVM: the need to ensure that operations can be safely restarted. For example, when deleting a large data structure, such as a tree, it must be removed in a way that it can be stopped and restarted (e.g., if the system were to crash, it must then be able to resume removal). To resume after a crash, they use a log of operations and replay it – a classic solution to the problem.
Figure 3 shows how they handle one of the complex consistency cases inherent in managing NVM: the need to ensure that operations can be safely restarted. For example, when deleting a large data structure, such as a tree, it must be removed in a way that it can be stopped and restarted (e.g., if the system were to crash, it must then be able to resume removal). To resume after a crash, they use a log of operations and replay it – a classic solution to the problem.
To make their goal of referential integrity work properly they utilize the programming language constructs to do this. The authors note they achieve this by using 128 bit pointer values (on a 64 bit system).
The paper describes their implementation in considerable detail. Again, as we would expect, the implementation yields substantially better performance than comparable systems backed by disks – this really shouldn’t come as a surprise, given the performance differential between disks and non-volatile memory. Even if they had used solid state disks (which existed but were rare in 2011) their results would have still be notably better. Figure 8 shows their performance information, comparing themselves against several other systems. One thing to note: they do not have NVM memory. They use a memory simulator to model the behavior of the system. The performance figures they provide surprised me: they are substantially faster than I would have expected. For PCM, they used a 67 nano-second (ns) read time and 215 ns write time. The paper explains how they obtained these values and how they validated them. For STTM (a different NVM technology) they reported 29 ns read and 95 ns write. As a baseline, their DRAM read time was 25 ns, and write time was 35 ns.
While these numbers were lower than I would have expected, the relative ratio is close to what I expected from other things that I have read: PCM memory is about 2.5 times slower for reads, and 10 times slower for writes. This is consistent with what the paper reports. I guess it’s time to update my mental “Jeff Dean” numbers. And indeed, it turns out that DRAM latency is around 15 ns.
The authors were able to modify memcached to use their library for persistence. They report that they were able to get within 8% of the original memcached. That seems like an excellent outcome.
All we need now are NVMs.
Mnemosyne: Lightweight Persistent Memory
Haris Volos, Andres Jaan Tack, Michael M. Swift, ASPLOS ’11 March 5-11, 2011.
The abstract starts us off in this brave new world:
New storage-class memory (SCM) technologies, such as phase-change memory, STT-RAM, and memristors, promise user-levelvaccess to non-volatile storage through regular memory instructions. These memory devices enable fast user-mode access to persistence, allowing regular in-memory data structures to survive system crashes.
So faster, doesn’t require privilege, works like memory, and persistent. Pretty fancy stuff.
File systems aren’t really constructed to have direct access to the disk from user applications. Generally it is done via an I/O interface: open, close, read, and write. But memory isn’t accessed in that fashion at all. So, how does this affect things? What do the services look like? What does it mean to take something everyone thinks of as transient and make it persistent?
Let’s start exploring!
Mnemosyne provides an explicit mechanism for exposing persistent memory to applications. This is done by extending the programming tools so they can declare something should be stored in persistent memory, or so that it can be dynamically allocated with the proviso that it be allocated from this persistent memory.
Thus, the default is that an existing application retains the same behavior – it does not use persistent memory. If an application wishes to use persistent memory it must be modified to do so. Mnemosyne will provide a basic service level, but it won’t change the behavior of existing applications (technical debt really does follow us around in this business).
It’s impressive: “… Mnemosyne can persist data as fast as 3 microseconds.” It makes existing applications modified to use it much faster. Figure 1 (from the paper) describes the architecture the authors created for Mnemosyne.
 This architecture envisions the persistent memory being exposed to the application through a persistence interface; the motivation for this is that merely having persistent memory is not enough. It requires additional work to ensure that it is crash resistant. In other words, the system can restore the state of the contents in memory to some well-defined consistent state.
This architecture envisions the persistent memory being exposed to the application through a persistence interface; the motivation for this is that merely having persistent memory is not enough. It requires additional work to ensure that it is crash resistant. In other words, the system can restore the state of the contents in memory to some well-defined consistent state.
This is something file systems routinely handle – the issues of persistence and recoverability. I often try to think about failure: how does failure manifest? How do I know that I can recover the state to a consistent spot and then proceed?
This is an uncommon concept for most application developers: they don’t need to worry about the contents of memory being “consistent” in the face of crashes because when the application crashes, the memory is lost.
Mnemosyne provides a model of consistency for applications by creating an explicit mechanism for providing crash consistence. Note that Mnemosyne won’t define those consistent states – the application must define what it means for its data structures to be consistent. What Mnemosyne offers are certain guarantees about the contents of memory.
The authors’ decision to virtualize their SCM is an interesting one: “[V]irtualization prevents a memory leak in one program from monopolizing a finite amount of SCM.” Thus, they stage SCM content to disk between processes. Consistency of data is provided by “ordering writes”. The authors identify four consistency mechanisms:
- Atomic variable update – update the data in place as a single all-or-nothing operation.
- Append updates – data is not written in place, but rather a new copy is written, such as it might be to the end of a log (such updates are ordered).
- Shadow updates – data is written to a new location and once done, the pointer to the old copy is updated to point to the new copy (e.g., via an atomic variable update). The authors point out there is a potential leak here that must be handled properly.
- In-place updates – used for data structures that can be modified in place; provided the operations are ordered.
Consistency guarantees for persistent memory are accomplished using processor semantics and mechanisms:
- A write through operation (e.g., a temporal move) that is written directly to memory.
- Memory fences that ensure strict ordering of operations before the fence relative to operations after the fence.
- Cache line flushes. The CPU stores memory inside the processor while it is acting upon it. In fact, a modern CPU has multiple levels of memory. The most expensive (and smallest) will be the Level 1 cache. It’s also the fastest. L2 cache is larger and slower than L1 cache. L3 cache is typically shared with all CPUs on the processor; it is the largest and slowest of the caches.
For storage people, some of this is familiar and some of it is different – instead of worrying about storage stack semantics we’re now worrying about processor cache semantics. One upside is that processor semantics are more rigidly enforced than storage semantics (e.g., disk drives that lie and say that the data has been written when it hasn’t.) One downside is that it’s a new failure domain. For anyone used to working with persistent storage, understanding the failure domain is vital. I suspect it is also different for people used to thinking about the processor perspective, since persistence isn’t usually something you have to reason about.
Mnemosyne implemented a persistent heap allocator, a modified version of Intel’s STM Compiler (we’ll see later that others had to move that work to other compilers because it is now abandoned), a logging mechanism, a persistent region mechanism, a transactional system (based upon TinySTM).
Their results are, of course, good. After all, if they had not been good, they wouldn’t have been published. They outperform BerkeleyDB (for some metrics). They demonstrated a fast and persistent red-black tree implementation. They show the benefits of asynchronous truncation.
Mnemosyne was a useful contribution because it was an early exploration into considering how we should use byte-addressable non-volatile memory. The library they built is used in future work as well, and this is a heavily cited paper.
The Log-Structured Merge Tree (LSM-Tree)
Patrick O’Neil, Edward Cheng, Dieter Gawlick, Elizabeth O’Neil in Acta Informatica, , Volume 33, Issue 4, pp 351–385.
This paper does not relate to non-volatile memory, but we will see Log-Structured Merge Trees (LSMTs) used in quite a few projects. From the abstract:
The log-structured mergetree (LSM-tree) is a disk-based data structure designed to provide low-cost indexing for a file experiencing a high rate of record inserts (and deletes) over an extended period. The LSM-tree uses an algorithm that defers and batches index changes, cascading the changes from a memory-based component through one or more disk components in an efficient manner reminiscent of merge sort. During this process all index values are continuously accessible to retrievals (aside from very short locking periods), either through the memory component or one of the disk components.
So LSMTs originate from concerns about the latency issues around disk drives.
In a nutshell, the challenge with disk drives are they have mechanical parts that must be moved in order to read the data. Data is written in concentric bands around the center. The angular velocity of the disk platter is the same, but of course the surface velocity is lowest towards the center and fastest towards the outer edge. The disk drive “head” is moved in and out to read from each of those concentric circles. Since it can only read what is beneath the head, it also must wait for the desired data to rotate under the head. This is one reason why faster disk drives (usually measured by the rotations-per-minute number) provide faster response times. On the other hand, faster disk drives generate more heat and are more expensive to build.
Thus, an important consideration for file systems working on rotating media is the latency to perform random access. Tape drives have the highest latency, since we have to reposition the tape to get to another location and read its data (there are other complexities as well, such as the fact that tape benefits most from streaming write). Hard disk drives (HDDs) are not so bad as tape drives in general (though SMR drives act much like tape drives, which is one reason I mention that here.) Solid State Disks are even better than disk drives, though even for an SSD random access is slower than sequential access – but both are much faster than HDDs.

Some of those papers that I have yet to cover describe the concept of a log-structured file system. One of the things that I learned when working on the Episode File System was that converting random I/O to sequential I/O was definitely a win (so was asynchronous logging). It is this observation: converting random I/O to synchronous I/O that provides the benefit of using journaling techniques (the “log”).

So LSMTs capitalize upon this advantage. Note that an LSMT is not a single data structure; rather it is a general technique for working with systems where insert and delete are the common operations, such as meta-data within a file system, or (key,value) tuples in a key-value store. It also points out that reading large sequential block is generally more efficient; they cite IBM when noting that a single page read from the DB2 Database takes approximately 10 milliseconds. A read of 64 continuous pages costs about 2 milliseconds per page (125ms total). So batching I/O operations is also an important mechanism for improving performance.
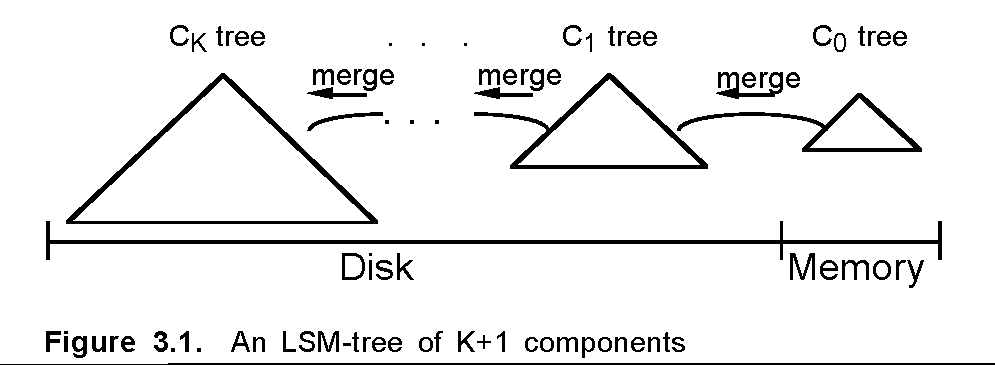
So what is an LSMT? “An LSM-tree is composed of two or more tree-like component data structures.” From there the authors describe their initial case: where one tree is memory resident and the other is disk resident. Note, however, this is the smallest set for a valid LSMT. Systems with more than two have been built – and one way to use non-volatile memory (NVM) is to add it as another layer to an LSMT.

Figure 2.1 (from the paper) shows the high level structure of the LSMT – a tree-like structure at each level of the storage hierarchy; these levels can have different characteristics, such as being ephemeral (in memory) or persistent (on disk, tape, SSD, etc.) Figure 2.2 provides greater detail, showing how data is merged from one level to the next (“rolling merge”). Figure 3.1 shows a generalization of the LSMT, in which data is migrated from one level of the storage hierarchy to the next.
Figure 6.1 then helps motivate this work: data that is seldom accessed (which is most of the data) is “cold” and can be stored in lower cost storage. Data that is frequently accessed (which is a small amount of the data) is “hot” and benefits from being stored in faster but more expensive storage. Indeed, there is a substantial body of work at this point that demonstrates how data tends to cycle from being hot to being cold. Thus, there is a period of migration for “warm” data. This also helps explain why having a multi-stage model makes sense. This behavior is quite general, in fact. Disk drives are constructed with caches on them. The cache is for the hot data, the disk storage for the cold data. SSDs are often structured with multiple classes of NVM; a small amount of expensive but fast NVM and then a larger amount of less expensive (often block oriented) NVM. Even CPUs work this way (as I will be discussing ad nauseum), where there are multiple levels of caching: L1 cache is small but very fast, L2 cache is larger and slower (and cheaper), L3 cache is again larger and slower. Then we get to memory (DRAM) which is even slower. That’s all before we get to storage!
This is quite a long paper: they describe how data is merged from one level to the next as well as do an in-depth analysis of cost versus performance. But I will leave ferreting out those details to the interested reader. I got what I came for: a basic description of the tiered nature of LSMTs and how we can use them to make storage more efficient without driving up costs.
Recent Comments